
Web Scraping Tools : How to get started with Beautiful Soup ?
TIL (Today I Learn) Series


Introduction
As a beginner in Data Science I usually make use of datasets to apply my skills and practice a lot. From my searches, I've discovered that there is a lot of data sources such as datasets (easily downloadable on Kaggle or Zindi ), existing files (csv, json, xlsx) from our laptops, web scraping, just to name a few.
I develop a strong interest for Web Scraping; and the first time I worked on a web scraping project, I used Twython, an easy-to-use tool for capturing data (tweets) from Twitter. Since then, I plan to read a lot about other tools that are used to do web scraping.
Today, I learn about one of those powerful tools : Beautiful Soup. In this article, I will share my understanding of the followings :
What's web scraping ?
What's Beautiful Soup ?
How to install Beautiful Soup ?
How to start with a practical example ?
What's web scraping ?
There's a huge quantity of data online especially on web pages that we need to extract to sometimes make some analysis. The process which consists in extracting a specific data for a specific purpose from a web page is called web scraping. Among the various tools used to do web scraping, there's one which is powerful and popular : Beautiful Soup.
What's Beautiful Soup ?
Actually, Beautiful Soup is a Python library used to pull out data from XML as well as HTML files. Sometimes, it can be combined with other libraries to ensure data extraction. Beautiful Soup has many advantages and the most important is about the number of hours or days of work it saves developers from.
How to install Beautiful Soup ?
You can install Beautiful Soup in a few steps. First, make sure you have Anaconda Command Line Prompt on your laptop. Then, you can run the following command :
pip install beautifulsoup4
How to start with a practical example ?
We are going to see basically how Beautiful Soup works. So, for that we'll use a simple HTML page I've created on my github. But before, let's import the libraries. As you read earlier, Beautiful Soup doesn't work alone and here we'll use another library named requests, an HTTP library. So, in your Jupyter Notebook environment, run the following commands :
import requests #pip install requests (if not installed)
from bs4 import BeautifulSoup as bs
Now, let's load the content of our html page by running the following command :
r = requests.get("https://modoukpea.github.io/Allo-Landing-Page/") #This is the link to my file, you can replace it with your own link.
# Passing the content to a BeautifulSoup Object
data = bs(r.content)
# Printing out the content of our page
print(data)
You should probably have something like this :
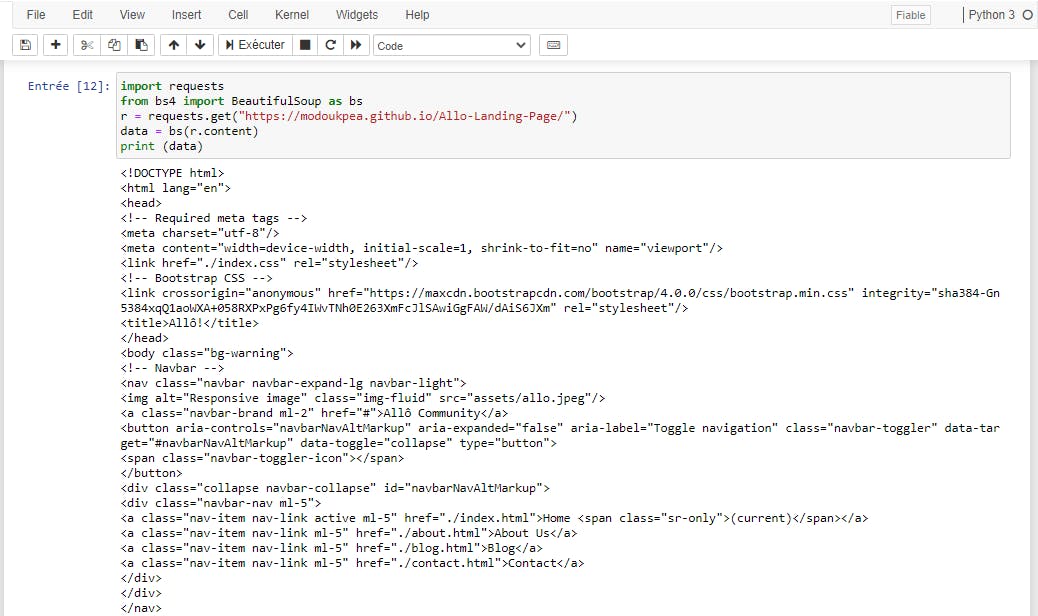
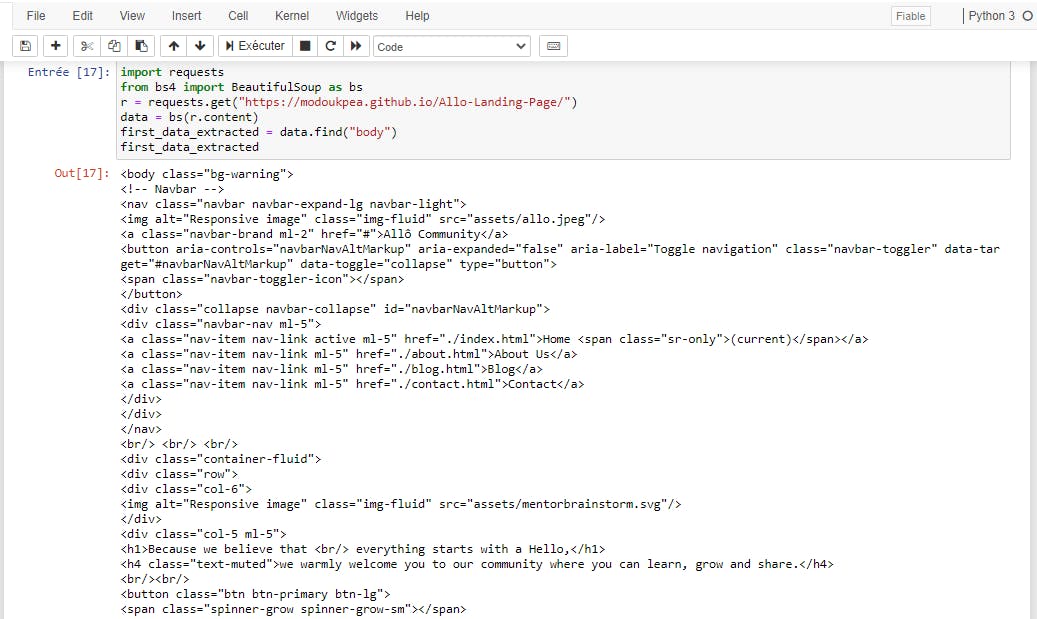
Using the find() method
find() is a method of the Beautiful Soup library that helps to extract a unique value based on the criteria you pass in parameters. Here's an example :
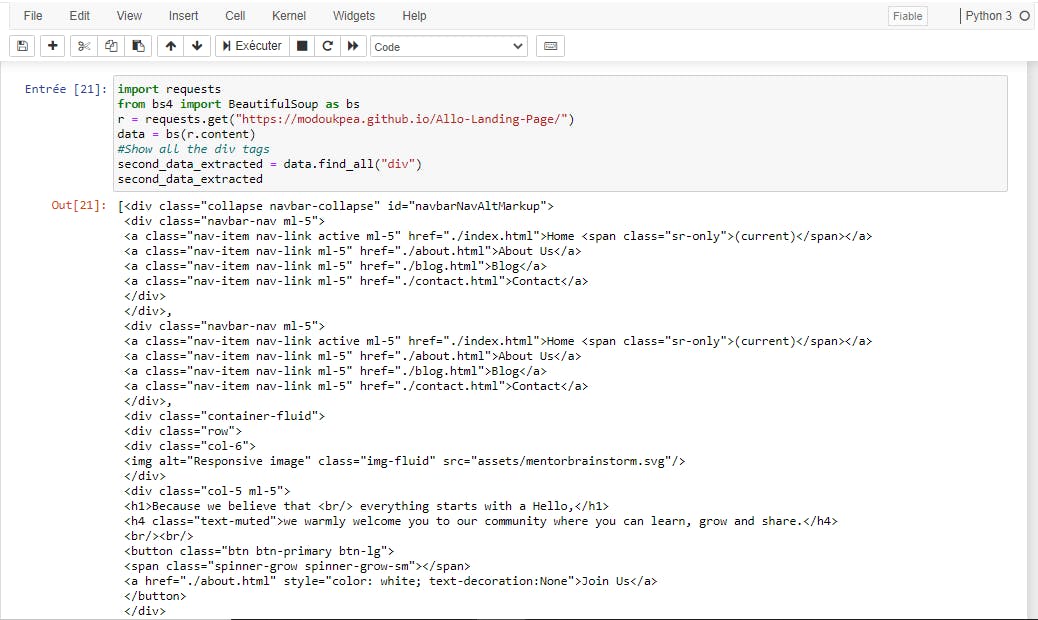
Using the find_all() method
find_all() method helps in extracting all the records that have the passed parameter in common. Here's a second example :
And many more functions, methods and syntax which are very helpful when it comes to extract data from a web page.
Conclusion
There are many tools online for web scraping and Beautiful Soup is among the popular. As you read, it's an open-source and easy-to-use tool you can learn more about as a beginner.
Hope this article is helpful !!!